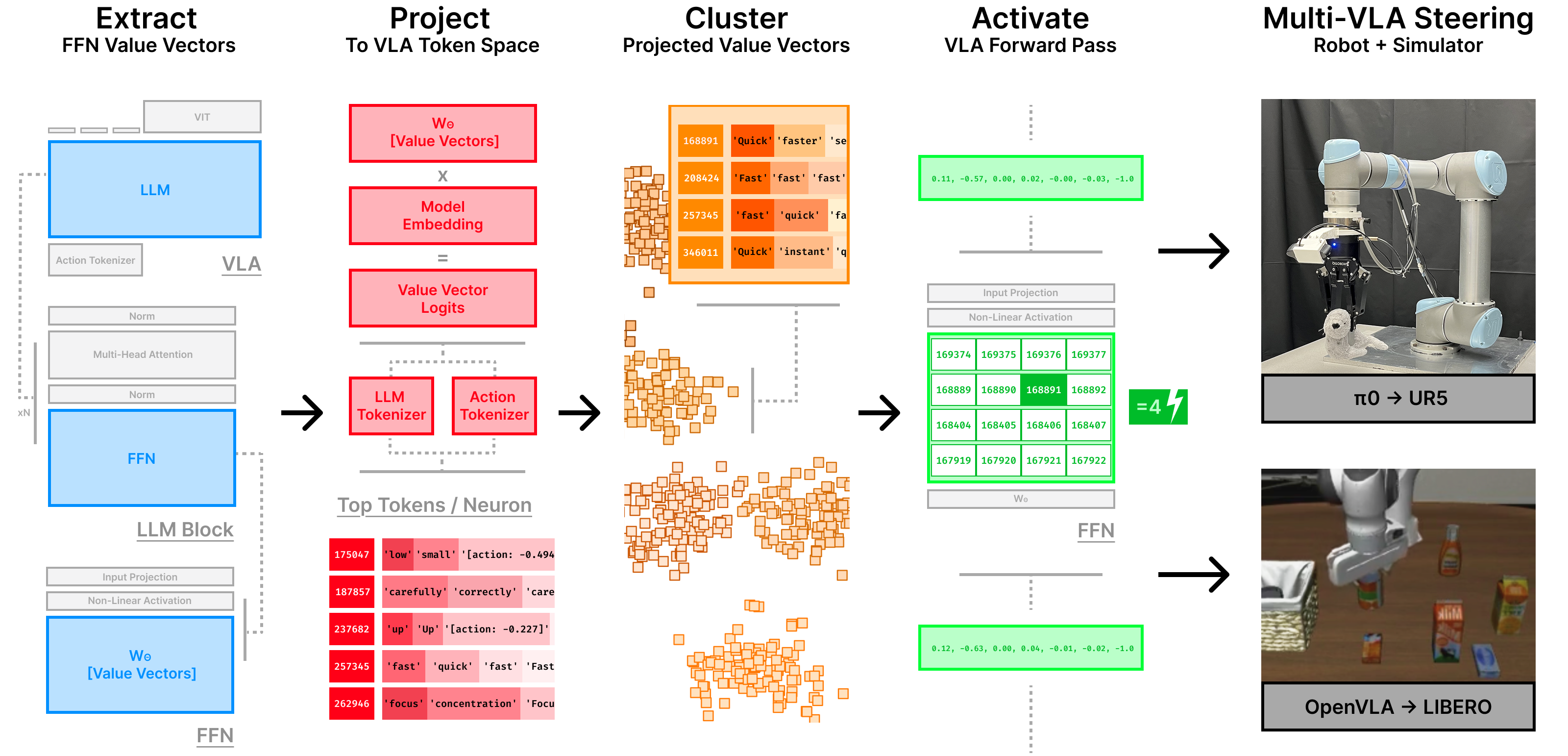
Motivated by advances in mechanistic interpretability for large language models, we introduce the first framework for interpreting and steering VLAs via their internal representations, enabling direct intervention in model behavior at inference time. We project feedforward activations within transformer layers onto the token embedding basis, identifying sparse semantic directions – such as speed and direction – that are causally linked to action selection. Leveraging these findings, we introduce a general-purpose activation steering method that modulates behavior in real time, without fine-tuning, reward signals, or environment interaction. We evaluate this method on two recent open-source VLAs, π0 and OpenVLA, and demonstrate zero-shot behavioral control in simulation (LIBERO) and on a physical robot (UR5). This work demonstrates that interpretable components of embodied VLAs can be systematically harnessed for control - establishing a new paradigm for transparent and steerable foundation models in robotics.
We introduce a method to probe the internal structure of VLA models by analyzing the feedforward layers of each transformer block. Each FFN computes:
Each fixed value vector \( w^{(i)}_\theta \) can be interpreted by what it contributes to the final output when strongly activated with a high activation coefficient \( [f_\theta(x)]_i \). By projecting these vectors to the model’s vocabulary, we identify semantically meaningful neurons — aligned with robot control concepts like up, slow, and careful.
We use this method to uncover four key insights into how VLAs internally represent and evolve their understanding of language and control.
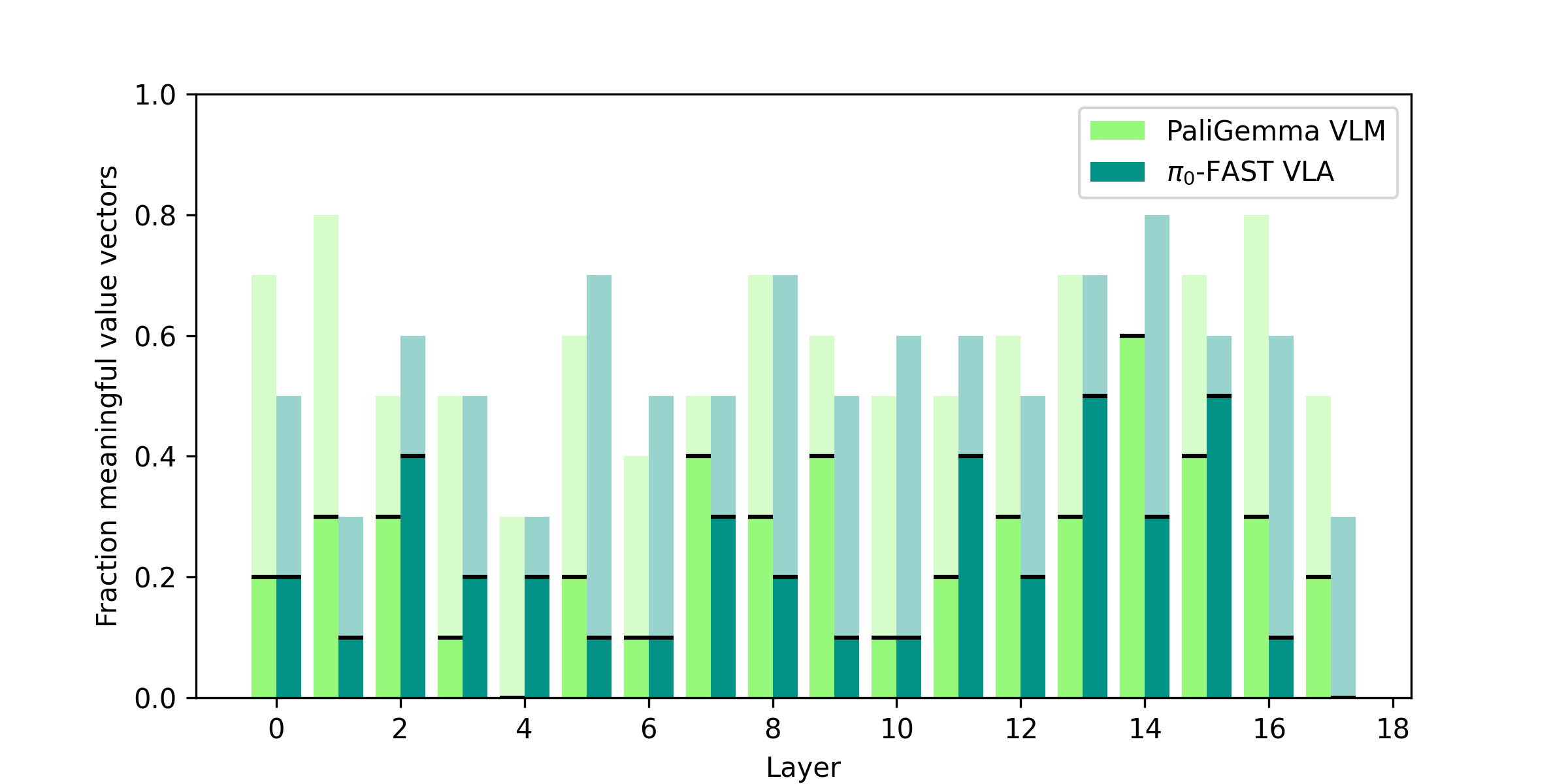
Meaningful patterns in top value vector tokens. VLA training does not substantially change the proportion of FFN value vectors which have interpretable patterns (top lighter bars) and semantically meaningful patterns (bold bottom bars) in their best-aligned tokens.
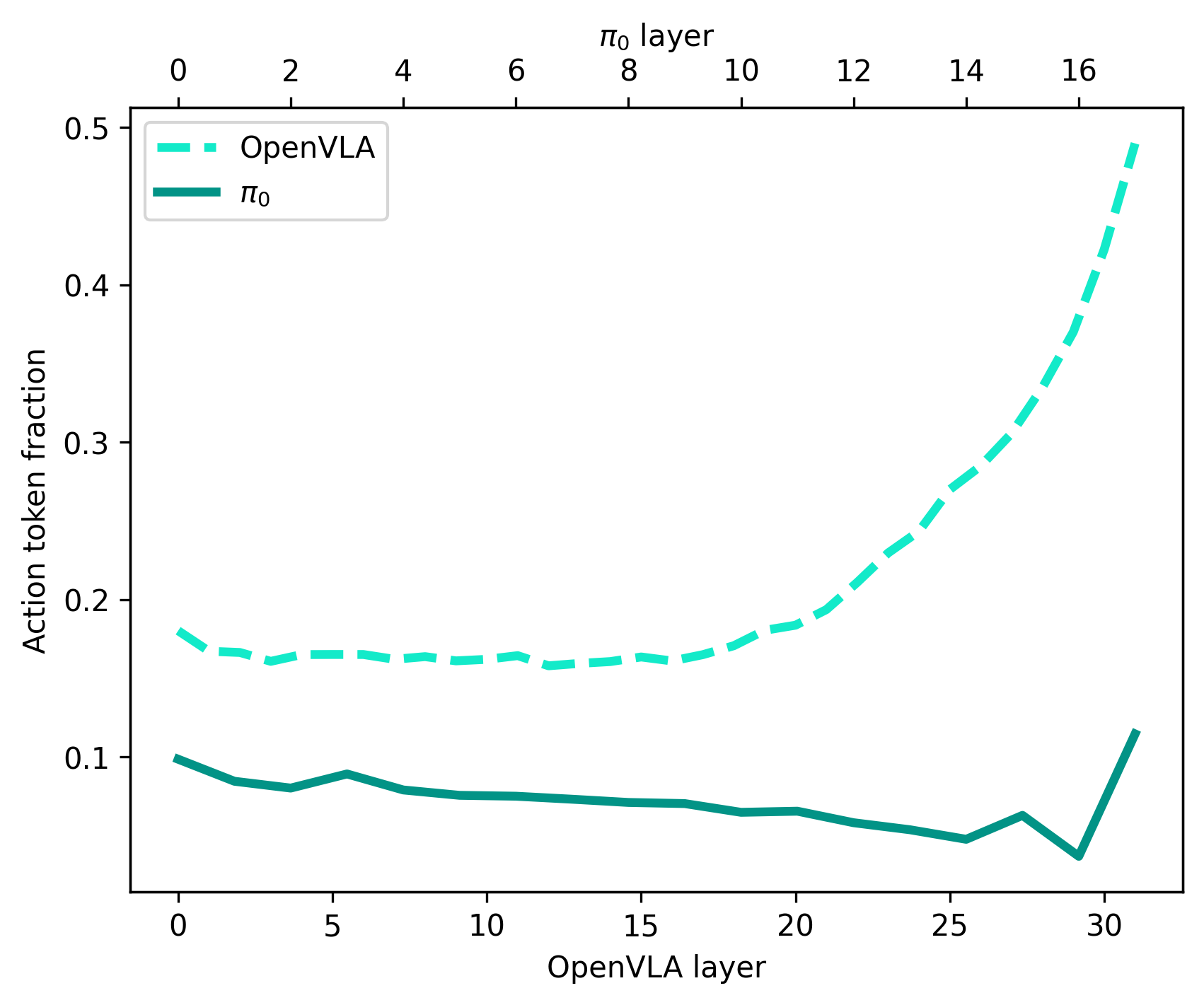
Action tokens are incorporated into every layer of the VLA. However, they make up the largest proportion of final layer value vectors.
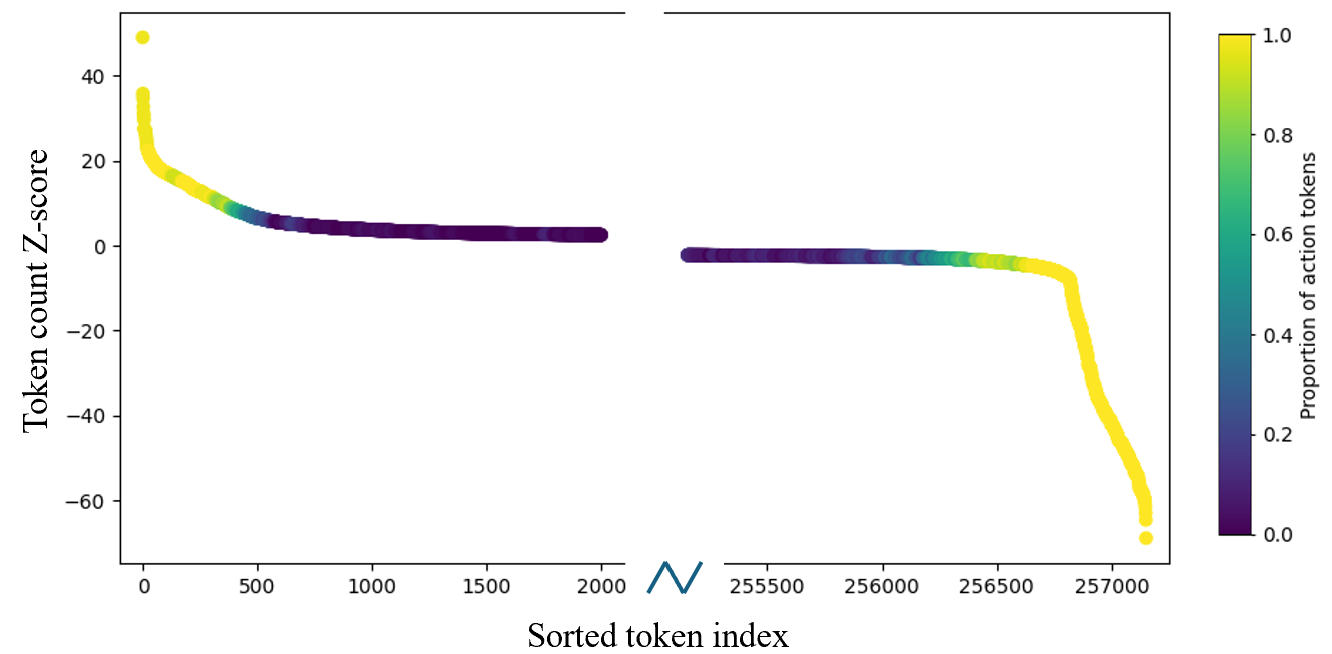
Task fine-tuning mainly affects action (not semantic) tokens. The most up-weighted and down-weighted tokens between the π0-FAST and π0-FAST-DROID-finetune models are action tokens.
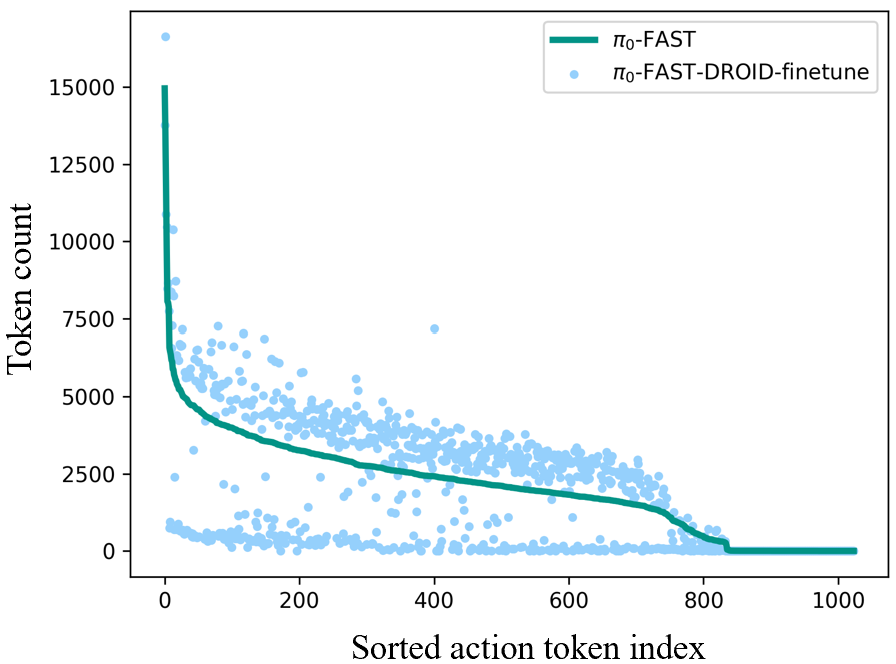
Fine-tuning induces a more specialized (less general) distribution of action tokens across value vectors.
We introduce interpretable activation-level steering for VLAs: a real-time control method that modifies selected FFN neurons in the VLA’s transformers — without fine-tuning or reward signals.
Following Equation (1), we override activations for a subset \( \mathcal{S} \) of control-themed neuron clusters using a scalar \( \alpha \), inducing a shift in the FFN's output:
\[ \tilde{f}_\theta^{(i)}(x) = \begin{cases} \alpha & \text{if } i \in \mathcal{S} \\ [f_\theta(x)]_i & \text{otherwise} \end{cases} \tag{2} \]
\[ \text{FFN}_{\text{steered}}(x) = \sum_i \tilde{f}_\theta^{(i)}(x) \cdot w_\theta^{(i)} \tag{3} \]
This shift propagates through the VLA and steers the final action distribution. Across VLAs, we implement this in either PyTorch (via FFN hooks) or JAX (via a modified FFN), enabling direct behavioral modulation grounded in semantic concepts retained by the VLA.
The robot achieves the natural language task within a lower work space.
π0-FAST : UR5
The robot achieves the natural language task within a higher work space.
π0-FAST : UR5
The robot achieves the natural language task at a faster speed.
π0-FAST : UR5
The robot achieves the natural language task at a slower speed.
π0-FAST : UR5
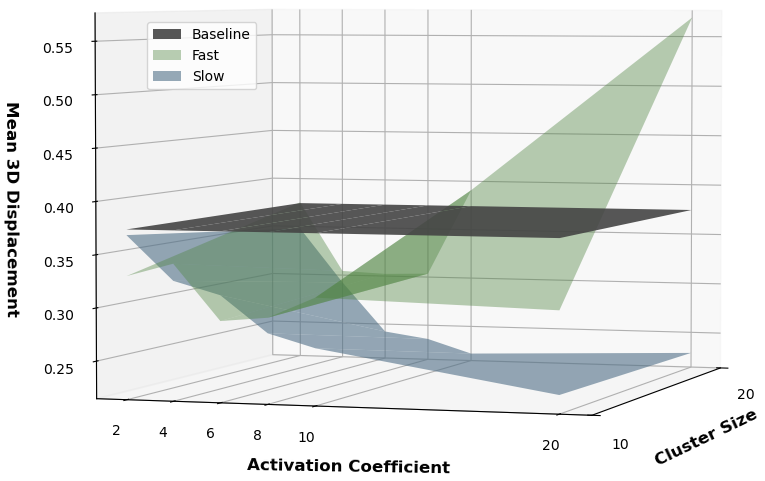
Fast clusters consistently lead to larger step-wise end-effector displacement.
OpenVLA : LIBERO-Long
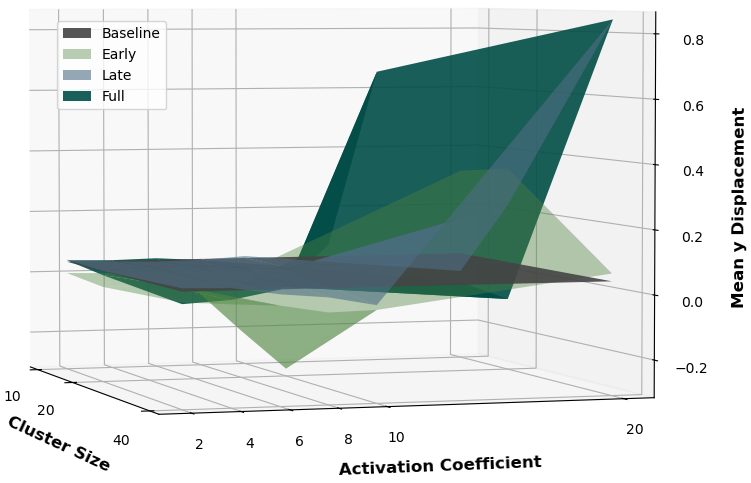
Clusters that include neurons from all layers consistently produce stronger motion effects.
OpenVLA : LIBERO-Long
@inproceedings{
haon2025mechanistic,
title={Mechanistic Interpretability for Steering Vision-Language-Action Models},
author={Bear H{\"a}on and Kaylene Caswell Stocking and Ian Chuang and Claire Tomlin},
booktitle={9th Annual Conference on Robot Learning},
year={2025},
url={https://openreview.net/forum?id=YvsUD8C9QS}
}This research was supported by the following programs:


